
")







“It’s very willing to sacrifice pieces if it’s better for the long term.”

Computers have been kicking our fragile human asses at chess for a couple decades now. The first time this happened was in 1996, when IBM’s Deep Blue was able to take down world champion Gary Kasperov. But a new study from Alphabet’s A.I. outfit DeepMind sheds light on just how limited in scope that early victory really was.
For one, Kasperov bounced right back, winning three games and drawing twice in a six game playoff, per an old Daily News report.
But much more notably, as DeepMind researcher Julian Schrittwieser tells Inverse, applications like Deep Blue were also programmed manually. This means that humans had to teach the A.I. everything it needed to know about how to handle every imaginable contingency. In other words, it could only ever be as good as the people programming it were. And while Deep Blue was obviously able to get pretty good at chess; give it another, similar, game like Go and it’d have been clueless.
Alpha Zero is completely different. In a new study published recently in the journal Science, the authors reveal how they were able to not just teach Alpha Zero how to beat humans at chess, but were able to teach Alpha Zero how to teach itself to master multiple games.
How to Teach A.I. To Teach Itself
Alpha Zero was developed using a technique called deep reinforcement learning. Essentially, this involves teaching the A.I. something very simple, like the basic rules of chess, and then doing that simple thing over and over and over again until it learns more complicated, interesting things like strategies and techniques.
“Traditionally … humans would take their knowledge about the game and try to code it in rules,” Schrittwieser, who’s been working on Alpha Zero for nearly four years, says. “Our approach is we initialize randomly, and then let it play games against itself, and from those games itself it can learn what strategies work.”
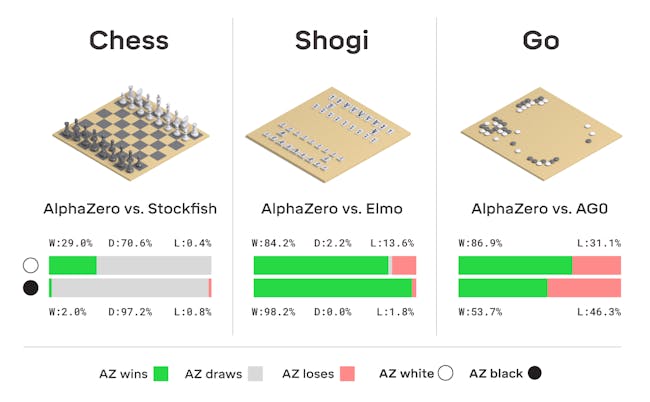
All Alpha Zero gets are the basic rules, and from there it learns how to win by playing itself. According to the new findings, it took only nine hours for Alpha Zero to master chess, 12 hours to master Shogi, and about 13 days to master Go. Because it’s playing itself, it’s essentially self-taught. It’s made mincemeat of all the world champion human-guided algorithms, beating the 2017 world champion in Shogi 91 percent of the time.
“It can independently discover interesting knowledge about the game,” Schrittwieser says. “It leads to programs that play more human-like.”
While its style is human-like and creative, however, it’s also likely optimal, he says, enough so that Alpha Zero should be able to dominate in pretty much any game in which it has access to all the available information. In fact, Alpha Zero is so sophisticated, we may need to move to an entirely different class of games in order to keep pushing the boundaries of how A.I. solves problems.
–
Why Alpha Zero Is So Good
A.I. researchers love using these games as testing grounds for ever-more sophisticated forms of algorithms for a few reasons. They’re elegant, and people have been playing them for hundreds of years, for one, meaning you’ve got lots of potential challengers to test your algorithm on. But they’re also complicated and intricate, too, which means they can serve as a stepping-stone to A.I. that can solve problems in the real world. Schrittwieser says the next area of research is creating an algorithm like Alpha Zero which can still make optimal decisions with imperfect information.
“In all these games, you know everything that’s happening,” he says. “In the real world, you might only know part of the information. You might know your own cards, but you don’t know your opponent’s, you have partial information.”
There are still a few boardgames capable of giving algorithms like Alpha Zero this kind of challenge, too — Schrittwieser mentioned Stratego, in which players hide their moves from one another — and Starcraft, which is another area of interest for DeepMind’s gaming-focused researchers.
“We want to make the problems that we tackle more and more complex,” he says. “But it’s always one dimension at a time.”
At the same time, Deep Mind’s next generation of computerized problem-solvers are already showing the potential to move from the gaming world into the real world. Earlier this week, it announced another algorithm called AlphaFold, which is capable of extrapolating a protein sequence into an accurate prediction of its 3D structure. It’s a problem that’s befuddled scientists for decades and could help open the door to cures for diseases ranging from Alzheimer’s to cystic fibrosis.